MPT树
以太坊MPT树
MPT树的全称是Merkle Patricia Trie,即默克尔前缀树。MPT树可以认为是默克尔树和前缀树的结合。事实也是如此,MPT树是以太坊结合了默克尔树和前缀树的特点而发明的一种非常重要的数据结构,因此它具备了默克尔树和前缀树的特点。
MPT树中的节点有以下4种类型:
- 扩展节点(Extension Node):只能有一个子节点。
- 分支节点(Branch Node):可以有多个节点。
- 叶子节点(Leaf Node):没有子节点。
- 空节点:空字符串。
节点的定义及说明
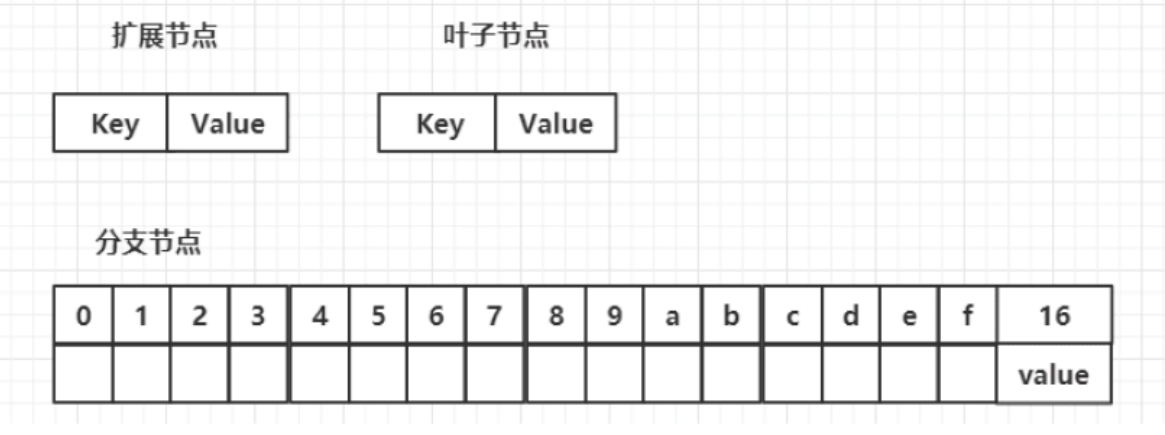
扩展节点
在代码中,扩展节点含有Key、Value和nodeFlag字段变量,定义如下:
gotype shortNode struct { Key []byte Val node flags nodeFlag }叶子节点
和扩展节点一样,也包含是Key、Value和nodeFlag字段变量,定义如下:
gotype shortNode struct { Key []byte Val node flags nodeFlag }分支节点
分支节点的内容是一个长度为17的数组。其中,前16位每个下标的值是十六进制的0~f、十进制的0~15,它们每位可能指向一个孩子分支,且允许不做任何指向,在最后的第17位是它自己的Value。因此,一个分支节点的孩子至多有16个。代码中的定义是:
gotype fullNode struct { Children [17]node flags nodeFlag }
节点字段变量的解释
Key只在扩展节点和叶子节点中存在。请注意,分支节点没有Key。Key就是Key,Value键-值对数据结构中的键。在以太坊中,不同的存储阶段,Key的值是不同的,有如下一些情况:
Raw编码
这种编码方式的Key是MPT对外提供接口的默认编码方式。例如,一个Key为cat,则其Raw编码就是['c','a','t'],转换成ASCII编码的表示方式就是[63,61,74]。
Hex十六进制编码
这种是MPT对内存中树节点的Key进行的编码方式,当数据项被插入到MPT树中时,Raw编码被转换成Hex编码。其诞生的原因是为了减少分支节点孩子的个数,由分支节点的定义和对应的示范图可以看出,分支节点最多有16个孩子节点。导致最多只有16个孩子节点的原因,就是使用了这种编码方式,不然的话会由于原来Key的8位范围取值是[0-(2^7-1)],即[0-127],意味着有128个位,从而对应到128个孩子节点这么多。为了减少可对应的孩子节点数,以太坊将原Key的高低共8位分拆成两个字节,以4位进行存储,而4位在十六进制中,最大能表示的是f,即其范围为[0-f],从而减小了每个分支节点的容量,但是在一定程度上增加了树的高度。
从Raw编码向Hex编码的转换规则是:
- 将Raw编码的每个字符根据高4位、低4位拆成两个字节。
- 若该Key对应节,点存储的是真实的数据项内容(该节点是叶子节,点),则在末位添加一个ASCⅡ值为16的字符作为终止标志符。
- 若该Key对应的节点存储的是另外一个节点的哈希索引(该节点是扩展节点),则不加任何字符。
例如某叶子节点的Key为 cat
Raw编码:['c','a','t'],转换成ASCII表示方式就是[63,61,74]
Hex编码: [0011,1111,0011,1101,0100,1010,0x10]=>[3,f,3,d,4,a,0x10]=>[3,15,3,13,4,10,16]
HP编码
全称为Hex-Prefix编码,即十六进制前缀编码,是MPT中的树节点被持久化存储到数据库层面时Key被编码的形式。当树节点被加载到内存中时,HP编码会被转换成Hex编码,对应从Hex编码到HP编码,刚好是一个对称的过程。
HP编码的规则如下:
- 若输入Key结尾为Ox10,则去掉这个终止符。
- Key之前补一个四元组,从右往左,这个四元组第0位作为区分奇偶信息,若Key长度为奇数则该位为1,若长度为偶数则该位为0。第1位区分节,点类型,叶子节点类型是1,其他是0。
- 如果输入Key的长度是偶数,就再添加一个四元组0x0000在第2点的四元组之后。
- 将原来的Key内容压缩,共8位,以高4位低4位进行合并输出。
例如,某叶子节点的Key为"cat"
它的Hex编码是[3,15,3,13,4,10,16]
根据第1点,因为16对应的十六进制表示就是0x10,所以去掉它,此时变为[3,15,3,13,4,10],共6个数值,所以长度是偶数。
根据第2点,Key之前补全四元组0x0,此时变为[0x0000,3,15,3,13,4,10],因为是节点类型,所以从右往左,第0位为0,第一位是1,变为[0x0010,3,15,3,13,4,10]。
根据第3点,Key的长度是偶数,则再添加一个四元组0x0在之前的四元组之后,变为[0x00100000,3,15,3,13,4,10]。
根据最后一点,压缩合并,变为[32,63,61,74],32就是二进制00100000的十进制数:2^5=32。此时再转为Hex编码就是[2,0,3,15,3,13,4,10]。
因为在HP编码情况下的Key加入了Prefix前缀,所以在细分Key内容的时候应该多出一个前缀码,如下图所示。
前缀的好处之一是能够标识这个节点的类型。
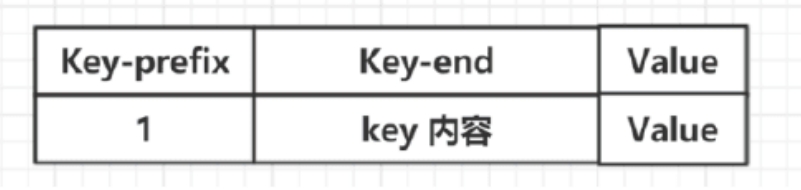
在前面叶子节点的Key为cat的例子中,通过HP编码计算出的[2,0,3,15,3,13,4,10],其Key-prefix就是2,Key-end是0,3,15,3,13,4,10。
Value是用来存储节点数值的,不同的节点类型,Value对应的值也不同,主要有下面几种情况:
- 叶子节点:Value存储的是一个数据项的内容,例如[name,LinGuanHong],Key是name,Value是LinGuanHong,在代码中对应于ValueNode。
- 扩展节点:Value存储的是其孩子节点在数据库中存储的哈希值,可以通过该哈希链接到其他节点。在代码中,对应hashNode类型。
- 分支节点:Value存储的是在当前分支节点结束时节点的数据值,在代码中对应于ValueNode.。
比如:Key有abc、abd、ab,根据前缀树的特点开始构建树,如下图所示。因为3个Key拥有公共的前缀ab,其中abc和abd还多出一个字符,可以对应在分支节点中,ab没有多出的字符,它刚好在分支节点中结束,此时分支节,点的Value存储的就是Key=ab节点的值。当没有节点在分支节点中结束时,那么分支节点的Value没有数据存储。
type nodeFlag struct{
hash hashNode // cached hash of the node (may be nil)
gen uint16 // cache generation counter
dirty bool // whether the node has changes that must be written to the database
}nodeFlag是分支节点、扩展节点和叶子节点在代码结构体中附带的字段,主要用于记录一些辅助数据,其代码中的定义如下:
- 节点哈希hash:若该字段不为空,则当需要进行哈希计算时,可以跳过计算过程而直接使用上次计算的结果(当节点变脏时,该字段被置空)。
- 脏标志dirty:当一个节点被修改时,该标志位被置为1。
- 诞生标志gen:当该节点第一次被载入内存中(或被修改时),会被赋予一个计数值作为诞生标志,该标志会被作为驱除节点的依据一一清除内存中
太老的未被修改的节点,防止占用的内存空间过多。
MPT树节点存储到数据库
MPT树节点存储到数据库,又称节点的持久化,这个过程需要计算出各个节点对应的RLP编码数据及节点的哈希值,其最终存储在键值对<k,v>数据库中的格式是:[节点哈希值,节点的RLP编码]。要注意区分,这里持久化的哈希值不是Ky的哈希值,而是节点RLP编码的哈希值。
此外,持久化的计算过程是一个递归过程,意味着这个计算是从MPT树的底部开始从下往上进行的。持久化的步骤是:
使用
RLP将节点的数据进行序列化编码。- 对叶子/扩展节点来说,该节点的RLP编码就是对其Key和Value数据一起进行编码。即rlp(Key + Value)。
- 对于分支节点,该节点的RLP编码是对其孩子列表对应的哈希值一起进行RLP编码,如果此时的分支节,点的Value对应的是valueNode,即有数值,那么RLP编码也要加入value,即rlp(childNode's hash + Value)。
在每个节点计算出各自的RLP编码后,再根据RLP编码计算出节点的哈希值。使用的是SHA256算法计算,即hash=sha256(rlp数据)。
对应<k,v>数据库中k=hash、v=rlp编码,进行节点的持久化存储。
持久化对应源码中的操作代码(代码文件位置是trie/hasher.go)如下所示:
func (h *hasher)store (n node, db *Database, force bool) (node, error) {
...
// rlp.Encode将节点node数据进行rlp编码,存储于tmp内,其中Key和Value都在内部
if err := rlp.Encode (&h.tmp, n); err != nil {
panic("encode error:"+err.Error())
}
...
if hash == nil {
hash = h.makeHashNode(h.tmp)// 使用sha256对rlp数据进行哈希计算
}
if db != nil {
db.lock.Lock()
hash := common.BytesToHash(hash)
db.insert(hash,h.tmp)//存储
}
}组建一棵MPT树
根据对MPT树的介绍,本节我们从插入第一个节点开始组建一棵MPT树,来对MPT树做一个整体的认识。
因为节点中的Key在不同阶段对应的编码形式并不相同,为了体现出Hex-Prefix编码,我们下面在构建的时候将HP编码加入到里面去。注意,在实际情况中,HP编码只有在节点持久化时才会用到,并出现Key-Prefix,而在内存层面的MPT树,节点的Key是Hex编码格式,此时还没有Key-Prefix。
用于构建MPT树的节点如下图所示。
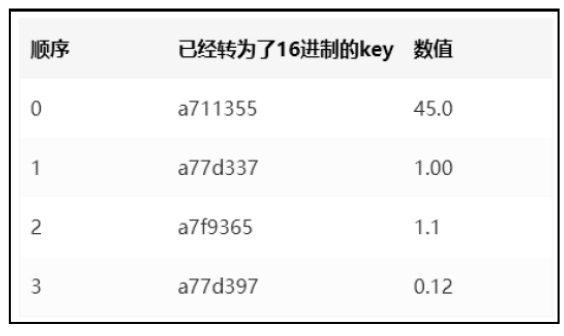
首先设根节点为Root。在构建的过程中,一般Root还没有生成,只有在整棵树都构建完成后才会从底部往上开始计算哈希值,最终算出根Root的哈希值。
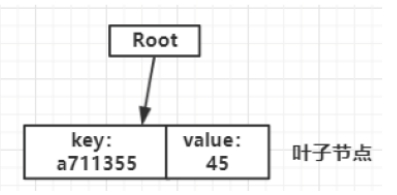
插入第一个节点<a711355,45>的时候,树如下图所示。
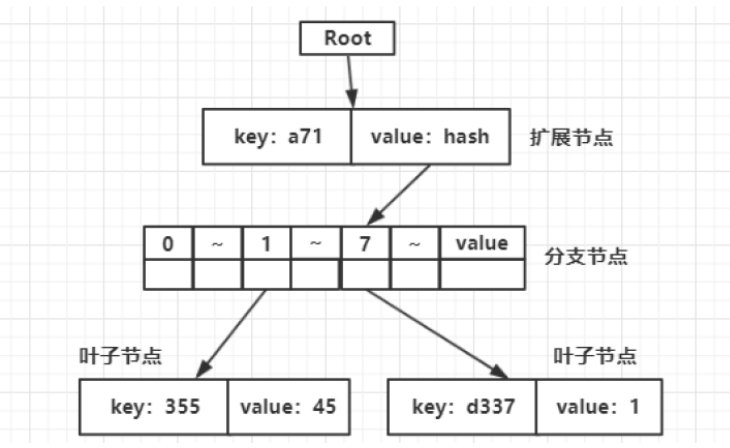
接着插入第二个节点<a77d337,1>。因为a77d337和a711355拥有公共的前缀a7,所以a7变为一个扩展节点,其value存储的是分支节点的哈希值,剩下的是两个叶子节点,树如下图所示。
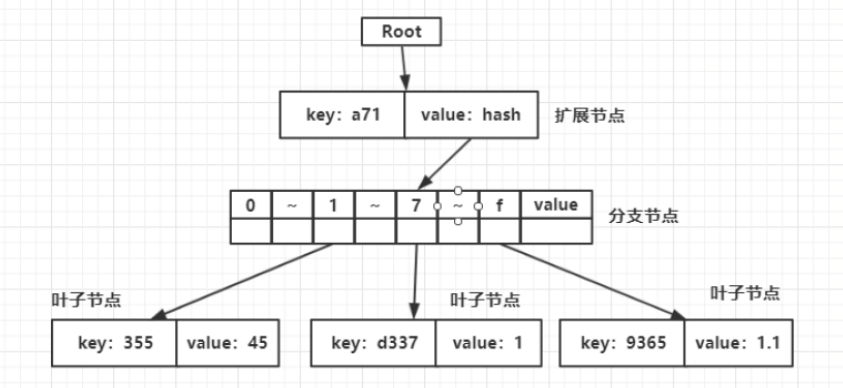
接着插入第三个节点<a79365,1.1>。因为这个节点和前两个节点都拥有前缀a7,所以它将会是分支节点中的一员,插入第三个节点之后的树如下图所示。
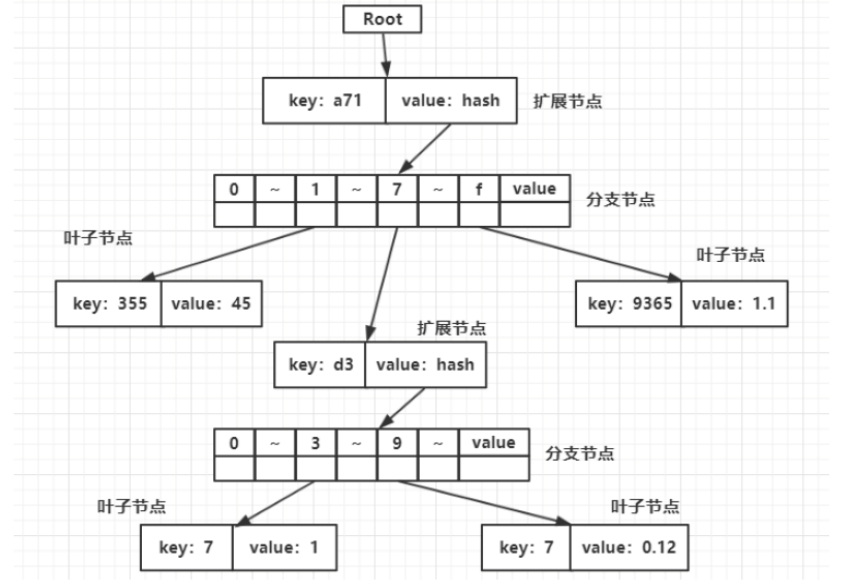
最后插入节点<a77d397,0.12>。因为a77d397和第二个节点的key(a77d337)在分支节点之后还存在d3的公共前缀,因此在它们之间要添加新的以key为d3的扩展节点,然后剩下的37与97还要添加一个分支节点。为什么是分支节点呢?因为扩展节点只能有一个孩子节点,而且我们现在还剩下37与97,所以为了容纳两个节点只能使用分支节点。最终的树如下图所示。
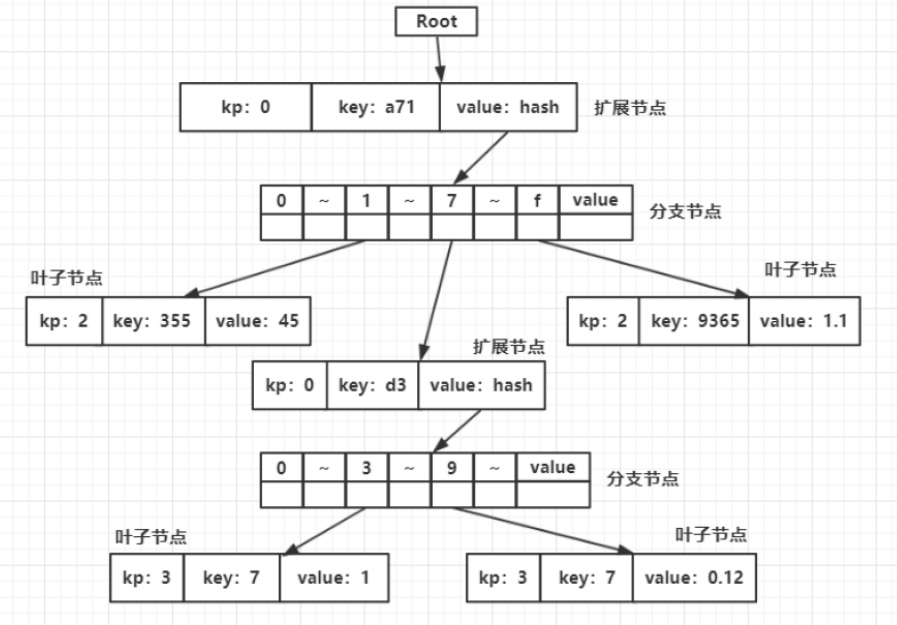
上图是最终构建好的MPT树。现在我们继续根据Hex-Prefix编码计算出扩展节点和叶子节点的Key-Prefix值。根据HP编码规则,最终得到的树如下图所示。
MPT树如何体现默克尔树的验证特点
因为MPT树拥有默克尔树的特点,所以MPT树也具备默克尔树依靠节点哈希值来校验数据合法性的特点。那么MPT树是怎样利用节点的哈希值来实现数据校验的呢?
由MPT树节点持久化的特点可知,特久化时每个节点会生成对应的哈希值,而MPT树校验过程所使用的节点哈希值就是持久化时使用RLP数据生成的哈希值。回顾持久化的步骤,节点生成哈希值的顺序是从底部开始的,父节点哈希值的生成依赖孩子节点的哈希值,孩子节点的哈希值由其自身的Key和Value生成,最后生成树的根节点的哈希值。
因此,MPT树在验证某个节点的合法性时也符合默克尔树从底部开始,逐级往上的验证过程,逐步生成父节点的哈希值,最后生成根节点的哈希值,然后和Root对比,判断它们是否相等,是则为合法节点,否则就是非法节点。