账户模型
账户模型
账户模型不仅存在于以太坊技术模块中,还存在于比特币技术模块中,它最直观的体现就是如何帮助钱包地址存储资产(代币)的数值。
在传统的服务器端的服务设计中,如果我们要为某一个用户记录他的资产余额信息,例如积分的余额,常见的做法就是直接在数据库中设置一张积分表,用来存储用户的积分。当积分有增加或使用的情况时,就对表格记录进行更新操作,表中剩下的数值就是对应的余额信息。上面的存储做法很容易理解和接受,但是在区块链中考虑到其分布式去中心化的特点,上述的做法并没有被采用,取而代之的技术方案有很多,其中比较具有代表性的是比特币的UTXO模型和以太坊的Account模型,我们把这类模型称为账户模型。
比特币UTXO模型
UTXO(Unspent Transaction Output,未花费的交易输出)是一种交易数据的存储模型。目前比特币所采用的就是它。
UTXO比较接近我们生活中钱财交易的记账模式,每一条符合UTXO模型的交易记录都拥有如下特点:
- 每笔交易拥有:输入部分(Input),输出部分(Output)
- 输出能够从
Unspend状态转为Spend状态,这个过程称为被使用。Spend状态的输出会成为另外一条符合UTXO模型交易的输入部分。 - 输出部分包含:已被花费的输出,即已经当作了后面交易的输入,此时的
Spend字段的值为true。没被花费的输出,即还没被作为后面交易的输入,此时的Spend字段的值为false。
只有尚未花费的输出才是所谓的UTXO一未花费的交易输出。已被花费的交易由于已经支付了,因此不是UXTO。
注意区分概念:UTXO模型不等于UTXO交易,后者是前者的真子集。
下面举例进一步阐述UTXO模型的特点。
假设一开始的时候A拥有100个BTC,B和C都拥有0个BTC,如下图所示。

现在A向B转账10个BTC。于是,A剩下90个BTC,而B得到了10个BTC,B的余额是10。此时的交易记录如下图所示,其内部包含一入一出的记录。
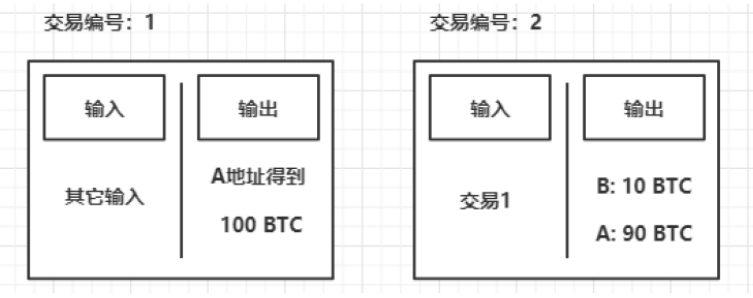
A的100个BTC不会凭空产生,它也是由其他输入赋予的,例如比特币挖矿所得。在交易2中,其输入部分为交易1的输出,此时交易1的输出变为Spend状态,交易1中的输出不再是UTXO交易,因为它己经作为了交易2的输入。交易2使用输入的100个BTC,分别输出给B和A。B获得10个BTC,A进行自己的找零操作,给了B的10个BTC后,自己剩下90个。此时在交易2中的B和A的输出都是UTXO,因为它们还没被花费。
当A又给C转账6个BTC和给B转账3个BTC,交易记录下图所示。
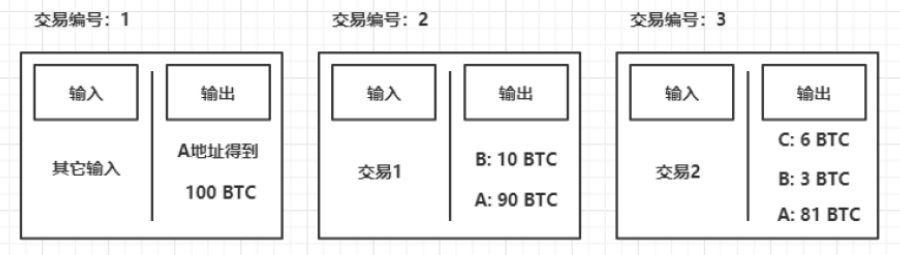
此时,交易2中A的输出将不再是UTXO,因为它成为了交易3的输入;而交易2中B的依然是UTXO,因为它还没作为其他交易的输入。
在往后的交易中便一直按照上面的记录形式来记录交易的输入和输出。
在上面的比特币例子中,UTXO模型存在几种情况,但不变的是其记录始终由输入和输出组成,在此之外还多了一个手续费的概念。一般地,输入和输出拥有下面的几种组合情况:
输入的条数比输出的多,输出的条数不只一条。
输出的条数比输入的多,输入的条数不只一条。
设sum是累计、输入数值为inputs、输出数值为ouputs、手续费是fee,那么比特币中的一笔交易恒满足:
texsum(inputs) - sum(ouputs) - fee = 0
比特币最初的代币产生是从挖矿中获取的,后续的代币因为不断地被交易而被分配到各个地址中去,根据UTXO的模型,可以知道:
- 每一笔交易的输出最终都能追寻一个一开始的输入。
- 交易的最初输入都来源于挖矿的收益地址,这个地址我们一般称为
CoinBase。
那么如何统计一个地址的BTC余额呢?其实就是统计其UTXO集合。如上图所示,B的BTC余额相关的UTXO分别在交易2和交易3中,为10+3=13个BTC。
在区块链中,不同的交易会被打包到不同的区块中去。这意味着,当我们需要计算某个地址中的余额时,需要遍历整个网络中所有与该地址相关的区块内的UTXO,汇总后便是它的余额。
UTXO模型明显的优点
- UTXO模型是无状态的,只要交易的签名合法,交易额正确,那么当交易被区块打包并广播确认后就会被直接进行存储。这会更容易应对并发转账的情况,因为没有类似序列号的东西,当一个地址拥有很多UTXO的时候,可以同时发起多笔交易。
- 除CoinBase交易外,交易的Input始终链接在某个UTXO后面,交易的先后顺序和依赖关系容易被验证。
UTXO模型明显的缺点
- 无法实现比较复杂的逻辑,可编程性差。例如,以太坊的智能合约功能就无法通过UTXO模型进行拓展实现。
- 性能问题,例如计算某个地址中的余额时,需要遍历整个网络中的全部相关区块,找到该地址的UTXO,当该地址相关的交易遍布区块较多时,时间复杂度将会剧增,获取余额的操作会出现比较慢的情况。
以太坊钱包地址存储余额的方式
以太坊区块Header结构体中Root变量的真实含义是,以太坊区块账户MPT树根节点的哈希值,区块账户MPT树中每个叶子节点的Key中存放的是以太坊钱包的地址值,叶子节点的Value对应的是以太坊的状态对象stateObject。而状态对象stateObject中又含有账户Account对象,在Account对象中有一个指针变量Balance,指向以太坊存放余额的内存地址,这也是以太坊的账户(Account)模型。
stateObject对象和Account对象在代码中的定义分别如下:
type stateobject struct {
address common.Address
addrHash common.Hash // 钱包地址的哈希变量形态
data Account // Account对象
db *StateDB
dbErr error
trie Trie // 首次访问,stateObject还没有被纳入树节点中,它会是空值
code // 只有当该账号是智能合约账号时,它才有值,对应的是合约的bytecode
...
}
type Account struct {
Nonce uint64
Balance *big.Int
Root common.Hash // 树根的哈希值
CodeHash []byte
}说明:
- Nonce:如果账户是用户钱包账户,Nonce代表的是该账户发出当前交易时的交易序列号;如果账户是智能合约账户,Nonce代表的是此账户创建的合约序号。
- Balance:该账户目前存放以太币余额的内存地址,请注意是以太币。
- Root:当前MPT树的根节点的哈希值。
- CodeHash:如果账户是用户钱包账户,该值为空,如果是智能合约账户,该值对应于当初发布智能合约代码的十六进制哈希值。
因为每个区块都对应一棵账户MPT树,就区块而言,它的账户MPT树中的账户数据都来源于被当前区块打包了的交易中,因为每笔交易中都存在着账户与账户之间的代币(Toke)资产转移记录,区块打包了某笔交易,便会提取该交易中的账户资产信息作为账户MPT树的某个节点插入到树中。
余额查询的区块隔离性
我们知道,账户的MPT树的叶子节点依赖于当前区块打包了的交易数组,换句话说,账户MPT树记录的账户信息是基于区块的。由于以太坊节点同步的有效区块来源于公有区块链,因此节点之间存在同步区块的快慢情况,这种情况常会造成余额查询出错。
下面我们通过一个例子来加以说明。
假设公链的最新区块高度是100,现在有两个以太坊节点A和B,节点A同步区块到了高度98,它把高度98打包了的交易中的账户信息逐个更新到<k,v>数据库中,而节点B同步区块到了高度100,节点B也保存好了账户信息。
此时,假如一个以太坊节点C共有8个ETH,且在之前发起了两笔交易,第一笔交易转账出去了3个ETH,第二笔交易转账出去了2个ETH,第一笔交易被区块98打包了,第二笔交易被区块100打包了。
此时节点D调用以太坊的RPC接口查询节点C的以太坊ETH余额,被查询到的节点刚好是B,那么节点B返回的将会是(8-3=5)的结果,而事实上节点C的真实余额是(8-3-2=3)个ETH。
余额的查询顺序
虽然账户数据会被持久化到<k,v>数据库中,但是在进行账户余额查询时并不是直接到<k,v>数据库中查找,因为账户MPT树持久化的键-值对是一个巨量的<k,v>数据集,直接查询需要很长时间,为加快查询速度,以太坊在钱包地址中代币(Token)余额查询上设置了三级缓存机制。
我们再来看stateObject结构体,其中有一个StateDB类型的db对象指针,该db指针对象就存储了基于内存的缓存Map。stateObject和StateDB在代码中的定义如下:
type stateobject struct {
address common.Address
addrHash common.Hash // 钱包地址的哈希变量形态
data Account // Account对象
db *StateDB
...
}
type StateDB struct{
db Database // leveldb对象
trie Trie // Trie树的第二级缓存
stateobjects map[common.Address]*stateObject // 第一级内存缓存
stateobjectsDirty map [common.Address]struct {}
...
}余额的查找顺序是:
第一级查找基于内存中的stateObjects对象,这里保留了近期活跃的账号信息。
第二级查找基于内存中的trie树。
第三级查找基于leveldb,即<k,v>数据库层。
第一级和第二级查找都是基于内存的,第二级的Trie体现在代码上是一个接口,在stateObject中,trie变量最终是一棵MPT树,它被用于在检验某一个钱包地址(address)的stateObject数据是否真的存在于某个区块中,其验证方式就是默克尔树的数据校验方式,这种设置优化了查找的整体时间复杂度。
UTXO模型和Account模型的对比
在计算方面,UTXO本身并没有过多的复杂计算,且在链上的计算也不多,由于Account模型是图灵完备的,支持智能合约,它的运算大部分在链上,计算相对来说比较复杂。因为智能合约部分对应的是从Solidity编程到编译的整个过程,通过代码能够实现一切可计算问题,所以Account模型比UTXO模型更具备可编程性。
在并发发起交易方面,UTXO模型支持并发,因为它不受交易编号顺序的限制,所以可以无须考虑顺序而以批量方式发起交易。Account模型因为存在Nonce交易序列号,所以它严谨地要求每笔交易的Nonce必须是递增的,也就是说,它的每笔交易都存在强关联性。
在交易重放方面,UTXO模型和Account模型都具备抵抗交易重发情况的功能。在UTXO模型中,因为每次交易的输入(Inputs)都和输出(Outputs)都存在从入到出的关系,如果一个相同的交易被重新发起,那么它所对应的输入在第一次的时候就己经被消费了,便会导致当前的交易失败,可以说是自身就带有抵抗交易重复的特点。相对来说,Account模型的做法是采用强顺序性的交易序列号Nonce来抵抗交易重发问题。
在存储方面,在UTXO模型中的交易记录存储在链上的区块中,这样时间一长,比特币的公链上,区块整体数据量会变得非常庞大。而Account模型存储在链上的只有MPT树的根节点的哈希值,实际的节点数据都持久地存放在每个节点本地的<k,v>数据库中。
在余额查询效率方面,因为UTXO模型并没有直接存储某个钱包地址的资产余额,而是通过多个输入输出交易来记录资产的变化,从而导致在查询钱包地址中的资产余额时须先获取到所有相关的UTXO交易记录的列表,再汇总统计。而Account模型使用了三级缓存的形式,即使缓存中没有记录,其最终也会到<k,v>数据库中直接查询余额信息。
综上所述,Account模型具备可编程性和灵活性,而UTXO则在简单业务和跨链上,有其独到和开创性的优势。