消息存储
存储组件
数据已经由生产者Producer发送给Kafka集群,当Kafka接收到数据后,会将数据写入本地文件中。
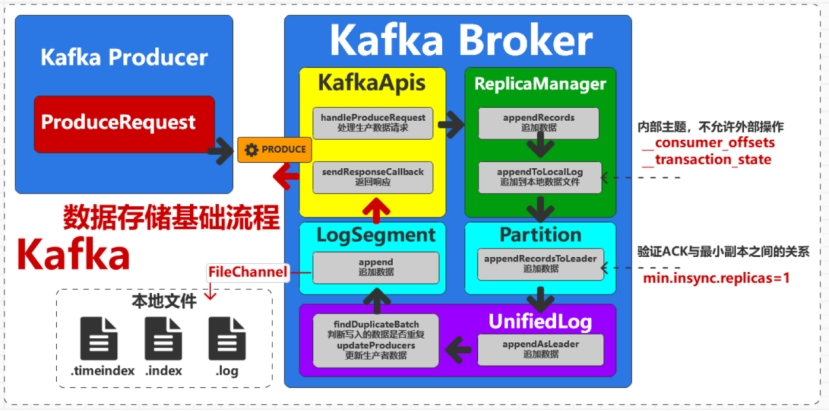
- KafkaApis : Kafka应用接口组件,当
Kafka Producer向Kafka Broker发送数据请求后,Kafka Broker接收请求,会使用Apis组件进行请求类型的判断,然后选择相应的方法进行处理。 - ReplicaManager : 副本管理器组件,用于提供主题副本的相关功能,在数据的存储前进行ACK校验和事务检查,并提供数据请求的响应处理
- Partition : 分区对象,主要包含分区状态变换的监控,分区上下线的处理等功能,在数据存储是主要用于对分区副本数量的相关校验,并提供追加数据的功能
- UnifiedLog : 同一日志管理组件,用于管理数据日志文件的新增,删除等功能,并提供数据日志文件偏移量的相关处理。
- LocalLog : 本地日志组件,管理整个分区副本的数据日志文件。假设当前主题分区中有3个日志文件,那么3个文件都会在组件中进行管理和操作。
- LogSegment : 文件段组件,对应具体的某一个数据日志文件,假设当前主题分区中有3个日志文件,那么3个文件每一个都会对应一个
LogSegment组件,并打开文件的数据管道FileChannel。数据存储时,就是采用组件中的FileChannel实现日志数据的追加 - LogConfig: 日志配置对象,常用的数据存储配置
| 参数名 | 参数作用 | 类型 | 默认值 | 推荐值 |
|---|---|---|---|---|
min.insync.replicas | 最小同步副本数量 | 推荐 | 1 | 2 |
log.segment.bytes | 文件段字节数据大小限制 | 可选 | 1G = 102410241024 byte | |
log.roll.hours | 文件段强制滚动时间阈值 | 可选 | 7天 =24 * 7 * 60 * 60 * 1000L ms | |
log.flush.interval.messages | 满足刷写日志文件的数据条数 | 可选 | Long.MaxValue | 不推荐 |
log.flush.interval.ms | 满足刷写日志文件的时间周期 | 可选 | Long.MaxValue | 不推荐 |
log.index.interval.bytes | 刷写索引文件的字节数 | 可选 | 4 * 1024 | |
replica.lag.time.max.ms | 副本延迟同步时间 | 可选 | 30s |
数据存储
Kafka Broker节点从获取到生产者的数据请求到数据存储到文件的过程相对比较简单,只是中间会进行一些基本的数据检查和校验。所以接下来我们就将数据存储的基本流程介绍一下:
ACKS校验
Producer将数据发送给Kafka Broker时,会告知Broker当前生产者的数据生产场景,从而要求Kafka对数据请求进行应答响应确认数据的接收情况,Producer获取应答后可以进行后续的处理。这个数据生产场景主要考虑的就是数据的可靠性和数据发送的吞吐量。由此,Kafka将生产场景划分为3种不同的场景:
- ACKS = 0:Producer端将数据发送到网络输出流中,此时Kafka就会进行响应。在这个场景中,数据的应答是非常快的,但是因为仅仅将数据发送到网络输出流中,所以是无法保证kafka broker节点能够接收到消息,假设此时网络出现抖动不稳定导致数据丢失,而由于Kafka已经做出了确认收到的应答,所以此时Producer端就不会再次发送数据,而导致数据真正地丢失了。所以此种场景,数据的发送是不可靠的。
- ACKS = 1:Producer端将数据发送到Broker中,并保存到当前节点的数据日志文件中,Kafka就会进行确认收到数据的响应。因为数据已经保存到了文件中,也就是进行了持久化,那么相对于ACKS=0,数据就更加可靠。但是也要注意,因为Kafka是分布式的,所以集群的运行和管理是非常复杂的,难免当前Broker节点出现问题而宕掉,那么此时,消费者就消费不到我们存储的数据了,此时,数据我们还是会认为丢失了。
- ACKS = -1(all):Kafka在管理分区时,会了数据的可靠性和更高的吞吐量,提供了多个副本,而多个副本之间,会选出一个副本作为数据的读写副本,称之为Leader领导副本,而其他副本称之Follower追随副本。普通场景中,所有的这些节点都是需要保存数据的。而Kafka会优先将Leader副本的数据进行保存,保存成功后,再由Follower副本向Leader副本拉取数据,进行数据同步。一旦所有的这些副本数据同步完毕后,Kafka再对Producer进行收到数据的确认。此时ACKS应答就是-1(all)。明显此种场景,多个副本本地文件都保存了数据,那么数据就更加可靠,但是相对,应答时间更长,导致Kafka吞吐量降低。
基于上面的三种生产数据的场景,在存储数据前,需要校验生产者需要的应答场景是否合法有效。
内部主题校验
Producer向Kafka Broker发送数据时,是必须指定主题Topic的,但是这个主题的名称不能是kafka的内部主题名称。Kafka为了管理的需要,创建了2个内部主题,一个是用于事务处理的__transaction_state内部主题,还有一个是用于处理消费者偏移量的__consumer_offsets内部主题。生产者是无法对这两个主题生产数据的,所以在存储数据之前,需要对主题名称进行校验有效性校验。
ACKS应答及副本数量关系校验
Kafka为了数据可靠性更高一些,需要分区的所有副本都能够存储数据,但是分布式环境中难免会出现某个副本节点出现故障,暂时不能同步数据。在Kafka中,能够进行数据同步的所有副本,我们称之为In Sync Replicas,简称ISR列表。
当生产者Producer要求的数据ACKS应答为-1的时候,那么就必须保证能够同步数据的所有副本能够将数据保存成功后,再进行数据的确认应答。但是一种特殊情况就是,如果当前ISR列表中只有一个Broker存在,那么此时只要这一个Broker数据保存成功了,那么就产生确认应答了,数据依然是不可靠的,那么就失去了设置ACK=all的意义了,所以此时还需要对ISR列表中的副本数量进行约束,至少不能少于2个。这个数量是可以通过配置文件配置的。参数名为:min.insync.replicas。默认值为1(不推荐)
所以存储数据前,也需要对ACK应答和最小分区副本数量的关系进行校验。
日志文件滚动判断
数据存储到文件中,如果数据文件太大,对于查询性能是会有很大影响的,所以副本数据文件并不是一个完整的大的数据文件,而是根据某些条件分成很多的小文件,每个小文件我们称之为文件段。其中的一个条件就是文件大小,参数名为:log.segment.bytes。默认值为1G。如果当前日志段剩余容量可能无法容纳新消息集合,因此有必要创建一个新的日志段来保存待写入的所有消息。此时日志文件就需要滚动生产新的。
除了文件大小外,还有时间间隔,如果文件段第一批数据有时间戳,那么当前批次数据的时间戳和第一批数据的时间戳间隔大于滚动阈值,那么日志文件也会滚动生产新的。如果文件段第一批数据没有时间戳,那么就用当前时间戳和文件创建时间戳进行比对,如果大于滚动阈值,那么日志文件也会滚动生产新的。这个阈值参数名为:log.roll.hours,默认为7天。如果时间到达,但是文件不满1G,依然会滚动生产新的数据文件。
如果索引文件或时间索引文件满了,或者索引文件无法存放当前索引数据了,那么日志文件也会滚动生产新的。
基于以上的原则,需要在保存数据前进行判断。
请求数据重复性校验
因为Kafka允许生产者进行数据重试操作,所以因为一些特殊的情况,就会导致数据请求被Kafka重复获取导致数据重复,所以为了数据的幂等性操作,需要在Broker端对数据进行重复性校验。这里的重复性校验只能对同一个主题分区的5个在途请求中数据进行校验,所以需要在生产者端进行相关配置。
请求数据序列号校验
因为Kafka允许生产者进行数据重试操作,所以因为一些特殊的情况,就会导致数据请求被Kafka重复获取导致数据顺序发生改变从而引起数据乱序。为了防止数据乱序,需要在Broker端对数据的序列号进行连续性(插入数据序列号和Broker缓冲的最后一个数据的序列号差值为1)校验。
数据存储
将数据通过LogSegment中FileChannel对象。将数据写入日志文件,写入完成后,更新当前日志文件的数据偏移量。
存储文件格式
数据日志文件
Kafka系统早期设计的目的就是日志数据的采集和传输,所以数据是使用log文件进行保存的。我们所说的数据文件就是以.log作为扩展名的日志文件。文件名长度为20位长度的数字字符串,数字含义为当前日志文件的第一批数据的基础偏移量,也就是文件中保存的第一条数据偏移量。字符串数字位数不够的,前面补0。
taketo@master:~/dev/kafka/broker/kafka_data/data/__consumer_offsets-1$ ls -al
total 16
drwxr-xr-x 2 taketo taketo 4096 Mar 13 22:03 .
drwxr-xr-x 37 taketo taketo 4096 Mar 14 14:41 ..
-rw-r--r-- 1 taketo taketo 10485760 Mar 13 22:03 00000000000000000000.index
-rw-r--r-- 1 taketo taketo 0 Mar 13 22:03 00000000000000000000.log
-rw-r--r-- 1 taketo taketo 10485756 Mar 13 22:03 00000000000000000000.timeindex
-rw-r--r-- 1 taketo taketo 8 Mar 13 22:03 leader-epoch-checkpoint
-rw-r--r-- 1 taketo taketo 43 Mar 13 22:03 partition.metadata我们的常规数据主要分为两部分:批次头 + 数据体
批次头
| 数据项 | 含义 | 长度 |
|---|---|---|
| BASE_OFFSET_OFFSET | 基础偏移量偏移量 | 8 |
| LENGTH_OFFSET | 长度偏移量 | 4 |
| PARTITION_LEADER_EPOCH_OFFSET | Leaader分区纪元偏移量 | 4 |
| MAGIC_OFFSET | 魔数偏移量 | 1 |
| ATTRIBUTES_OFFSET | 属性偏移量 | 2 |
| BASE_TIMESTAMP_OFFSET | 基础时间戳偏移量 | 8 |
| MAX_TIMESTAMP_OFFSET | 最大时间戳偏移量 | 8 |
| LAST_OFFSET_DELTA_OFFSET | 最后偏移量偏移量 | 4 |
| PRODUCER_ID_OFFSET | 生产者ID偏移量 | 8 |
| PRODUCER_EPOCH_OFFSET | 生产者纪元偏移量 | 2 |
| BASE_SEQUENCE_OFFSET | 基础序列号偏移量 | 4 |
| RECORDS_COUNT_OFFSET | 记录数量偏移量 | 4 |
| CRC_OFFSET | CRC校验偏移量 | 4 |
批次头总的字节数为:61 byte
数据体
| 数据项 | 含义 | 长度 |
|---|---|---|
| size | 固定值 | 1 |
| offsetDelta | 固定值 | 1 |
| timestampDelta | 时间戳 | 1 |
| keySize | Key字节长度 | 1(动态) |
| keySize(Varint) | Key变量压缩长度算法需要大小 | 1(动态) |
| valueSize | value字节长度 | 1(动态) |
| valueSize(Varint) | Value变量压缩长度算法需要大小 | 1(动态) |
| Headers | 数组固定长度 | 1(动态) |
| sizeInBytes | 上面长度之和的压缩长度算法需要大小 | 1 |
表中的后5个值为动态值,需要根据数据的中key,value变化计算得到。
# 此处以数据key=key1,value=value1为例。
# 压缩长度算法:
中间值1 = (算法参数 << 1) ^ (算法参数 >> 31));
中间值2 = Integer.numberOfLeadingZeros(中间值1);
结果 = (38 - 中间值2) / 7 + 中间值2 / 32;
假设当前key为:key1,调用算法时,参数为key.length = 4
中间值1 = (4<<1) ^ (4>>31) = 8
中间值2 = Integer.numberOfLeadingZeros(8) = 28
结果 = (38-28)/7 + 28/32 = 1 + 0 = 1
所以如果key取值为key1,那么key的变长长度就是1
# 追加数据字节计算
批次头 = 61
数据体 = 1 + 1 + 1 + 4 + 1 + 6 + 1 + 1 + 1 = 17
总的字节大小为61 + 17 = 78
# 如果我们发送的数据是两条为(key1,value1),(key2,value2)的数据, 那么Kafka当前会向日志文件增加的数据大小为:
# 追加数据字节计算
第一条数据:
批次头 = 61
数据体 = 1 + 1 + 1 + 4 + 1 + 6 + 1 + 1 + 1 = 17
第二条数据:
# 因为字节少,没有满足批次要求,所以两条数据是在一批中的,那么批次头不会重新计算,直接增加数据体即可
数据体 = 1 + 1 + 1 + 4 + 1 + 6 + 1 + 1 + 1 = 17
总的字节大小为61 + 17 + 17 = 95数据含义
查看 Kafka 发送的消息落在哪个日志文件
确认 Kafka 日志存储路径,默认路径通常是
/tmp/kafka-logs,取决于配置文件server.properties中log.dirs配置项找到主题和分区对应的日志文件,主题
test的分区0对应的日志目录shell# __consumer_offsets-31 [2025-03-14 07:12:03,945] INFO [GroupCoordinator 0]: Preparing to rebalance group test-consumer-group in state PreparingRebalance with old generation 0 (__consumer_offsets-31) (reason: Adding new member consumer-test-consumer-group-1-5ee09f22-25f2-4761-9741-7fd91d483f1a with group instance id None; client reason: not provided) (kafka.coordinator.group.GroupCoordinator) [2025-03-14 07:12:03,946] INFO [GroupCoordinator 0]: Stabilized group test-consumer-group generation 1 (__consumer_offsets-31) with 1 members (kafka.coordinator.group.GroupCoordinator)查看日志文件内容
Kafka 的日志文件是二进制格式,不能直接通过文本编辑器查看。可以使用 Kafka 自带的工具
kafka-dump-log.sh来解析日志文件。shell# 查看日志内容 /opt/bitnami/kafka/bin/kafka-dump-log.sh --files /bitnami/kafka/data/__consumer_offsets-31/00000000000000000000.log --print-data-log # 日志详情 Dumping /bitnami/kafka/data/__consumer_offsets-31/00000000000000000000.log Log starting offset: 0 baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1741874633140 size: 375 magic: 2 compresscodec: none crc: 3015700659 isvalid: true | offset: 0 CreateTime: 1741874633140 keySize: 23 valueSize: 282 sequence: -1 headerKeys: [] key: test-consumer-group payload:consumerrangeCconsumer-test-consumer-group-1-fa39b6b5-abde-41e8-97e4-445b2274059d????Cconsumer-test-consumer-group-1-fa39b6b5-abde-41e8-97e4-445b2274059d??consumer-te/10.45.13.200????test????test???? baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 375 CreateTime: 1741874645160 size: 375 magic: 2 compresscodec: none crc: 838901288 isvalid: true | offset: 1 CreateTime: 1741874645160 keySize: 23 valueSize: 282 sequence: -1 headerKeys: [] key: test-consumer-group payload:consumerrangeCconsumer-test-consumer-group-1-fa39b6b5-abde-41e8-97e4-445b2274059d????Cconsumer-test-consumer-group-1-fa39b6b5-abde-41e8-97e4-445b2274059d??consumer-te/10.45.13.200????test????test???? baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 750 CreateTime: 1741874714635 size: 123 magic: 2 compresscodec: none crc: 2407384435 isvalid: true | offset: 2 CreateTime: 1741874714635 keySize: 23 valueSize: 32 sequence: -1 headerKeys: [] key: test-consumer-group payload:consumer????????
| 数据项 | 含义 |
|---|---|
| baseOffset | 当前batch中第一条消息的位移 |
| lastOffset | 最新消息的位移相对于第一条消息的唯一增量 |
| count | 当前batch有的数据数量,kafka在进行消息遍历的时候,可以通过该字段快速的跳跃到下一个batch进行数据读取 |
| partitionLeaderEpoch | 记录了当前消息所在分区的 leader 的服务器版本(纪元),主要用于进行一些数据版本的校验和转换工作 |
| crc | 当前整个batch的数据crc校验码,主要用于对数据进行差错校验的 |
| compresscode | 数据压缩格式,主要有GZIP、LZ4、Snappy、zstd四种 |
| baseSequence | 当前批次中的基础序列号 |
| lastSequence | 当前批次中的最后一个序列号 |
| producerId | 生产者ID |
| producerEpoch | 记录了当前消息所在分区的Producer的服务器版本(纪元) |
| isTransactional | 是否开启事务 |
| magic | 魔数(Kafka服务程序协议版本号) |
| CreateTime(data) | 数据创建的时间戳 |
| isControl | 控制类数据(produce的数据为false,事务Marker为true) |
| compresscodec | 压缩格式,默认无 |
| isvalid | 数据是否有效 |
| offset | 数据偏移量,从0开始 |
| key | 数据key |
| payload | 数据value |
| sequence | 当前批次中数据的序列号 |
| CreateTime(header) | 当前批次中最后一条数据的创建时间戳 |
数据索引文件
Kafka的基础设置中,数据日志文件到达1G才会滚动生产新的文件。那么从1G文件中想要快速获取我们想要的数据,效率还是比较低的。通过前面的介绍,如果我们能知道数据在文件中的位置(position),那么定位数据就会快很多,问题在于我们如何才能在知道这个位置呢。
Kafka在存储数据时,都会保存数据的偏移量信息,而偏移量是从0开始计算的。简单理解就是数据的保存顺序。比如第一条保存的数据,那么偏移量就是0,第二条保存的数据偏移量就是1,但是这个偏移量只是告诉我们数据的保存顺序,却无法定位数据,不过需要注意的是,每条数据的大小是可以确定的。既然可以确定,那么数据存放在文件的位置起始也就是确定了,所以Kafka在保存数据时,其实是可以同时保存位置的,那么我们在访问数据时,只要通过偏移量其实就可以快速定位日志文件的数据了。
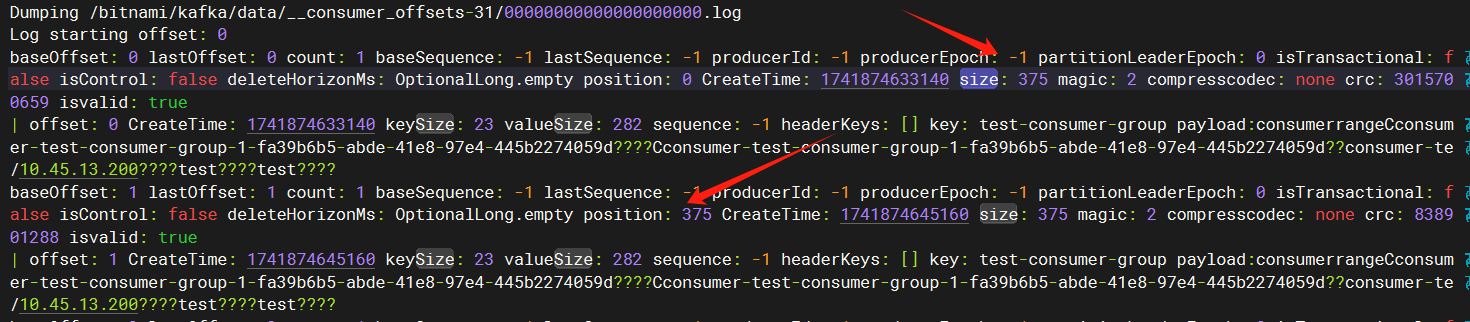
上一条数据的大小375字节,下条数据的存储位置就是从375开始
不过这依然有问题,就是数据量太多了,对应的偏移量也太多了,并且主题分区的数据文件会有很多,那我们是如何知道数据在哪一个文件中呢?为了定位方便Kafka在提供日志文件保存数据的同时,还提供了用于数据定位的索引文件,索引文件中保存的就是逻辑偏移量和数据物理存储位置(偏移量)的对应关系。并且还记得吗?每个数据日志文件的名称就是当前文件中数据䣌起始偏移量,所以通过偏移量就可以快速选取文件以及定位数据的位置从而快速找到数据。这种感觉就有点像Java的HashMap通过Key可以快速找到Value的感觉一样,如果不知道Key,那么从HashMap中获取Value是不是就特别慢。道理是一样的。
Kafka的数据索引文件都保存了什么呢?咱们来看一下
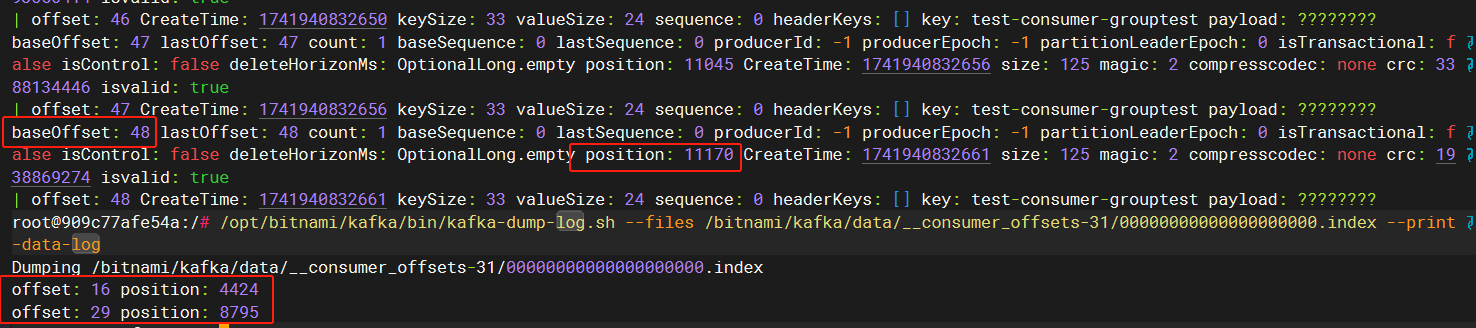
通过图片可以看到,索引文件中保存的就是逻辑偏移量和物理偏移量位置的关系。
有了这个索引文件,那么我们根据数据的顺序获取数据就非常的方便和高效了。不过,相信大家也注意到了,那就是索引文件中的offset并不连续。那如果我想获取offset等于3的数据怎么办?其实也不难,因为offset等于3不就是offset等于2的一下条吗?那我使用offset等于2的数据的position + size不就定位了offset等于3的位置了吗,当然了我举得例子有点过于简单了,不过本质确实差的不多,kafka在查询定位时其实采用的就是二分查找法。
不过,为什么Kafka的索引文件是不连续的呢,那是因为如果每条数据如果都把偏移量的定位保存下来,数据量也不小,还有就是,如果索引数据丢了几条,其实并不会太影响查询效率,比如咱们之前举得offset等于3的定位过程。因为Kafka底层实现时,采用的是虚拟内存映射技术mmap,将内存和文件进行双向映射,操作内存数据就等同于操作文件,所以效率是非常高的,但是因为是基于内存的操作,所以并不稳定,容易丢数据,因此Kafka的索引文件中的索引信息是不连续的,而且为了效率,kafka默认情况下,4kb的日志数据才会记录一次索引,但是这个是可以进行配置修改的,参数为log.index.interval.bytes,默认值为4096。所以我们有的时候会将kafka的不连续索引数据称之为稀疏索引。
数据时间索引文件
某些场景中,我们不想根据顺序(偏移量)获取Kafka的数据,而是想根据时间来获取的数据。这个时候,可没有对应的偏移量来定位数据,那么查找的效率就非常低了,因为kafka还提供了时间索引文件,咱们来看看它的内容是什么

通过图片,大家可以看到,这个时间索引文件起始就是将时间戳和偏移量对应起来了,那么此时通过时间戳就可以找到偏移量,再通过偏移量找到定位信息,再通过定位信息找到数据不就非常方便了吗。